Towards the end of my mid-2019 job search, I was down to joining the Google Go team or Sourcegraph. Sourcegraph ultimately won due to cultural factors - the most important of which was the ability to build 100% in the open. All documents were public by default. Technical and product RFCs (and later PR/FAQs) were drafted, reviewed, and catalogued in a public Google Drive folder. All product implementation was done in public GitHub repositories.
Today, the sourcegraph/sourcegraph repository went private. This is the final cleaving blow, following many other smaller chops, on the culture that made Sourcegraph an attractive place to work. It’s a decision for a business from which I resigned, and therefore have no voice. But I still lament the rocky accessibility of artifacts showing four years of genuine effort into a product that I loved (and miss the use of daily in my current role).
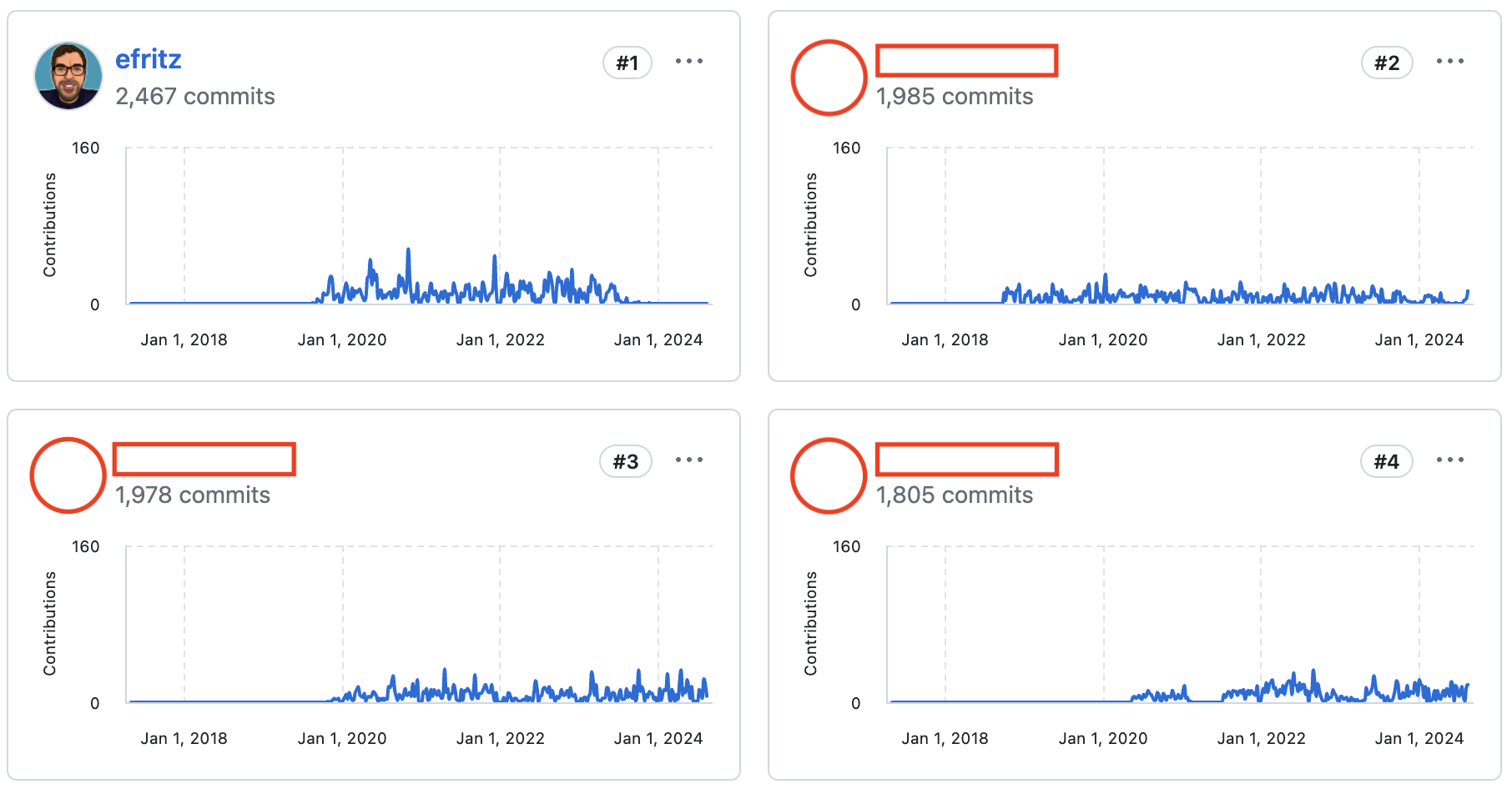
On the bright side, I’ve cemented my place on the insights leaderboard for the remainder of time.
sourcegraph/sourcegraph-public-snapshot for the time being.Keeping references alive
Over my tenure at Sourcegraph I’ve done a fair bit of writing for the engineering blog, which I’ve inlined into this website for stable reference. It’s interesting to see what people are trying to build and, for an engineer, how they’re trying to build it. Much of my writing used links into relevant public code as a reference.
All of these links are now broken.
There’s a common saying that cool URIs don’t change. In a related sense, I have the hot take that cool articles don’t suddenly start rotting links. I’m going to break at least one of these best practices, and I can’t do anything about the first one. So I’ll attempt to preserve as much information in this writing as possible by moving these links into a repository under my influence.
I had a feeling this would be a risk a while ago, so I had forked sourcegraph/sourcegraph into efritz/sourcegraph in preparation. Given the fork, it should be easy enough job to do a global find-and-replace of one repository name with another at this point and mission accomplished, right?
Unfortunately, no. I had links to code on the main branch, but also links to pull requests and commits within pull requests. Forks don’t inherit pull requests (problem #1). And commits not directly referenced by a branch of your fork are visible as only as long as they’re part of the repository network (problem #2).

I had wondered what happens to forks when a repository is deleted or changes visibility and found some calming information in the official GitHub documentation:
In other words, a public repository’s forks will remain public in their own separate repository network even after the upstream repository is made private. This allows the fork owners to continue to work and collaborate without interruption. […] If a public repository is made private and then deleted, its public forks will continue to exist in a separate network.
My fork will continue to exist (yay), but the source repository becoming inaccessible might take commits outside of the main branch with it. I need to ensure that these commits are part of the new repository network.
Scraping for relevant commits
Step one is to find all the commits I care about. I ran the following Go program to iterate through all of my pull requests on the source repository and write their payloads to disk for further processing.
| |
This program yielded 2,645 files with pull request metadata. I then used jq to read these JSON payloads and extract data for subsequent steps.
| |
This script creates three files:
pr_ids.txtis a flat list of GitHub identifiers, which are used in URLs. Since the list endpoint returns only enough data to render a pull request list, we’ll need to fetch additional information (intermediate commits) for each pull request by its ID.commits.txtis a flat list of git SHAs that were a result of merging a PR into the target branch (not alwaysmain). These commits may or may not be in the forked repository network, depending on the merge target. These should be synced over.replace_pairs.txtcontains pairs of of pull request identifier and its merge commit. This will later be used to mass replace/pull/{id}with/commit/{sha}. Since pull requests can’t be linked directly anymore, I can at least link to the full pull request contents.
Next, I ran a second program (with the same preamble as the program above) to list all the non-merge commits of each pull request. Based on the pants-on-head way I work, these will mostly be WIP. commits, but sometimes I did a better job and (possibly) linked directly to these.
| |
Running go run . >> commits.txt dumped these commits onto the end of the file and completes the set of Git SHAs that need to be brought into the repository network for stable reference.
Bringing commits into the new repository network
Given the warning above (“does not belong to any branch on this repository”), it should be sufficient to ensure that my fork has a branch containing each relevant SHA I’d like to retain access to.
Bash here does a good enough job since all we’re doing is a bunch of git operations in sequence.
| |
Rewriting references
At this point I should be safe and have some target to link to in my fork for each reference to a pull request or commit in the source repository. Now I just have to figure out how to automate that process (there are at least 275 code references over 15 files and I’m not doing that by hand).
Ironically, I used my own thing instead of Cody to figure out how to use xargs correctly for this task.
| |
Now I think we can say mission accomplished and I hope my dead links detector stops throwing a fit after all these changes.