It’s finally happened.
The most obnoxious restriction (by a very wide margin) related to administration of a Sourcegraph instance no longer applies. Sourcegraph instances (v3.20 or newer) are now able to upgrade directly to a future release, without the requirement to hit every minor release along the way.
A recent peek at our customer instance distribution showed that 70% of our self-hosted customers are on a “historic” release of Sourcegraph (older than two months). Larger customer instances also tend to approach upgrades a bit more cautiously, adding significant weight to the use of older releases. Note that Sourcegraph v3.20 was released fairly early in the most recent pandemic era, and we’ve spent the last two years of that era shipping improvements and building new features and workflows for an on-prem audience that was largely unable to benefit from the effort.
Multi-version upgrades, in contrast to the “standard upgrade” approach, use the migrator tool to perform the sequence of schema and in-place data migrations that would happen if the user were to perform a chain of upgrades that hit every minor release on the way to their target. This tool makes upgrading directly to our 4.0 release a technical feasibility for the vast majority of our customers.
At first glance, it may seem that multi-version upgrades are simply “standard upgrades in a for loop.” While that is the basic idea, there’s also a world of nuance surrounding it. Let’s dive in.
The migration journey
At the start of this journey, we used golang-migrate to handle the details of our migrations. This tool would detect the current “schema state” of the database (stored in a forcibly created table with at most one row) and apply any migrations that were defined strictly after the currently reported state. This process would happen on application startup, generally no-oping after the first run that actually applied any missing migrations.
Each migration exists on disk as a pair of SQL files: one for the upgrade direction, and one for the downgrade direction. Each migration is defined in the same directory and ordered absolutely by a sequential numeric prefix. Unit tests ensure that the sequence has no gaps and that no migrations define the same prefix. The order of migration application is thereby determined by lexicographical ordering of the migration filenames.
This process didn’t cause any clearly attributable problems for years. Around the time we started a serious hunt-to-kill effort for flaky tests in our CI pipelines, we started also seeing initialization timeouts we could attribute to reading and applying every single migration we’ve ever defined back to back:

Because this problem would only get worse with time, we began to squash migration definitions by replacing the set of definitions at the head of the sequence with a single (yet equivalent) migration file. For Sourcegraph v3.9.0, we squashed definitions that were also defined in Sourcegraph v3.7.0 into a single file. This cut startup time with an empty database from 20s to 5s and also reduced the chance of hitting the startup timeout in our testing environment.
Note that we are unable to squash migration definitions that are undefined in the source version of an upgrade. Doing so would make it impossible for the previous release to determine which migration definitions to apply. Squashing in the manner described above guarantees that none of the migration definitions in the upgrade path from the previous minor version would be altered.
Unfortunately, this absolutely throws a wrench in the works for multi-version upgrades. But let’s deal with that later. For now, we’ll discuss the remaining evolutions of the migration definition files and let the wrenches form a huge pile we can take care of all at once.
In what turns out to be prerequisite work for making multi-version upgrades a possibility, we engineered what was basically a drop-in replacement for golang-migrate. While the original goal was to separate application deployment and startup into individual (but related) concepts, it also allowed us maximum flexibility in how we defined and organized migrations on disk.
Because golang-migrate supported so many database systems, its design catered to the common features. As it happens, transactions were not one of the common features. Our replacement was designed only to support Postgres, which allowed us to introduce implicit transactions so that explicit BEGIN; and COMMIT; were not necessary in the migration definitions themselves.
In a related change, we explicitly marked migration definitions that contain indexes that are created concurrently. As we’ve recently learned, concurrent index creation interacts with long-running transactions in ways that can appear unintuitive at the application level. Most notably, an index cannot be created concurrently within a transaction, and the concurrent index creation will block as long as there is a transaction that outlives the index creation. Marking these migrations statically allows us to apply these migrations in a distinct manner so that these properties do not end up deadlocking the migration flow.
In an unrelated change, we explicitly marked privileged migrations. Privileged migrations contain certain operations that require elevated or superuser privileges, such as enabling a Postgres extension. Marking these migrations statically allows us to present reduced-privileged users with the required manual steps to perform during the migration process.
In order to keep track of the various migration metadata, we reorganized migration definitions into directories, each with three files: up.sql, down.sql, and metadata.yaml, as shown in the following image. Also of particular interest is the introduction of two entirely new and distinct database schemas controlled by the same migration infrastructure (codeintel and codeinsights).
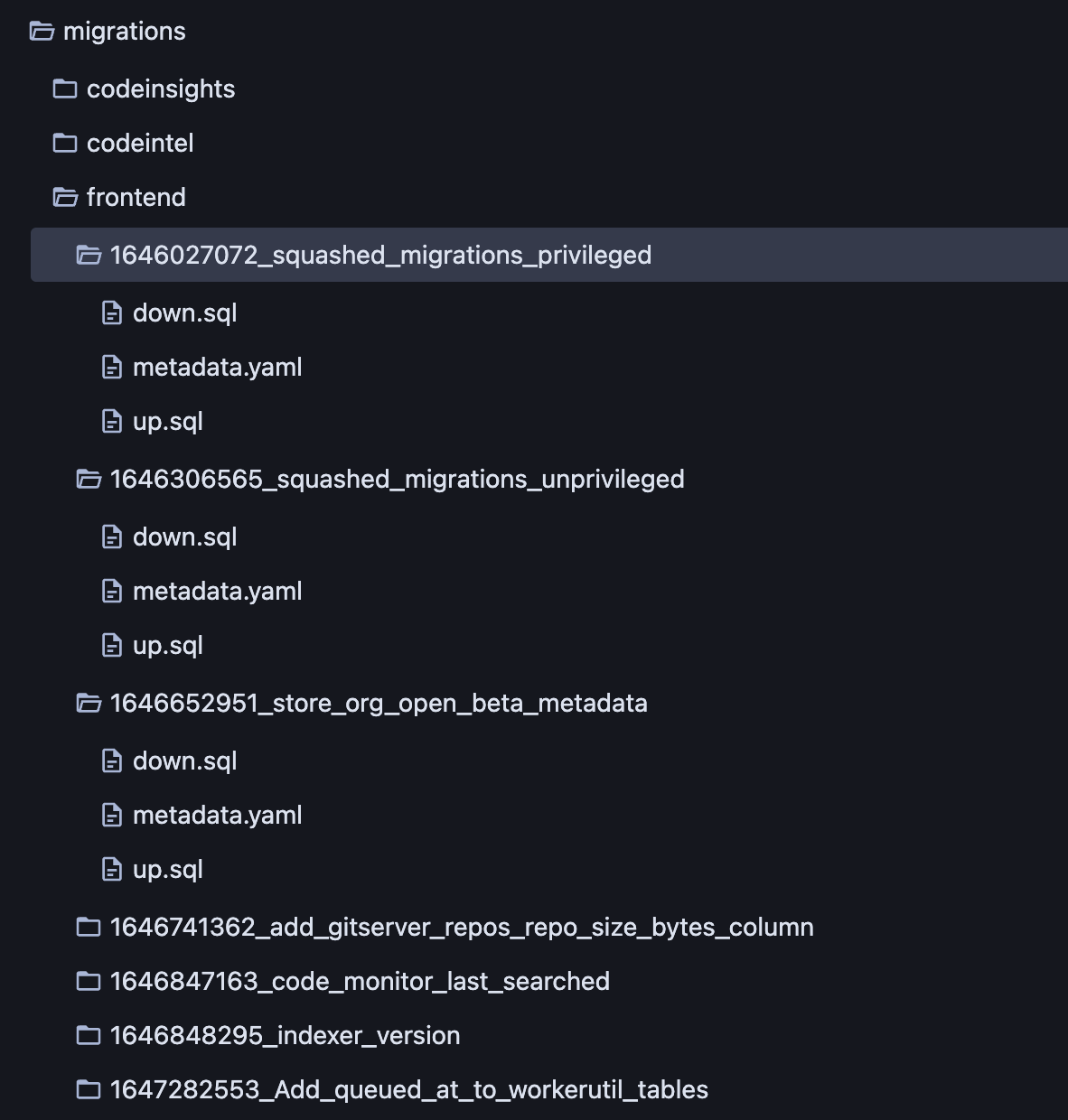
In what is likely the largest departure from golang-migrate, we allowed migrations to define multiple parents. This allows our migration definitions to form a directed acyclic graph (instead of an absolutely ordered list). Note that in the image above our migrations no longer form a gapless sequence, and a topological sort over the migration graph is done to determine an application order.
Well that seemed like a bunch of work for no payoff. Why do that at all? Short answer: engineering ergonomics. When we had a gapless sequence we would frequently run into merge conflicts when two engineers added migrations around the same time. Since each branch did not contain the other’s migration, they would both choose the same sequence number. Because of limitations in our CI (no build queues and no non-stale base branch merge requirement), this conflict would, the majority of the time, be caught only after both branches had been merged and validation errors turned the main branch to go red.
The following image shows a reduced (but fairly accurate) migration graph over several minor releases. When a new migration is created, it chooses its own parents: the set of migration definitions that do not yet have any children. In this formulation, if two engineers add migrations around the same time, they may share a parent, but they also have distinct identifiers (with very high probability). They don’t conflict, and should be able to be run in either order relative to one another as they were both developed in independent branches. Setting parents in this manner allows us to track explicit dependencies: the set of migrations that were already defined at the time the new migration was created.
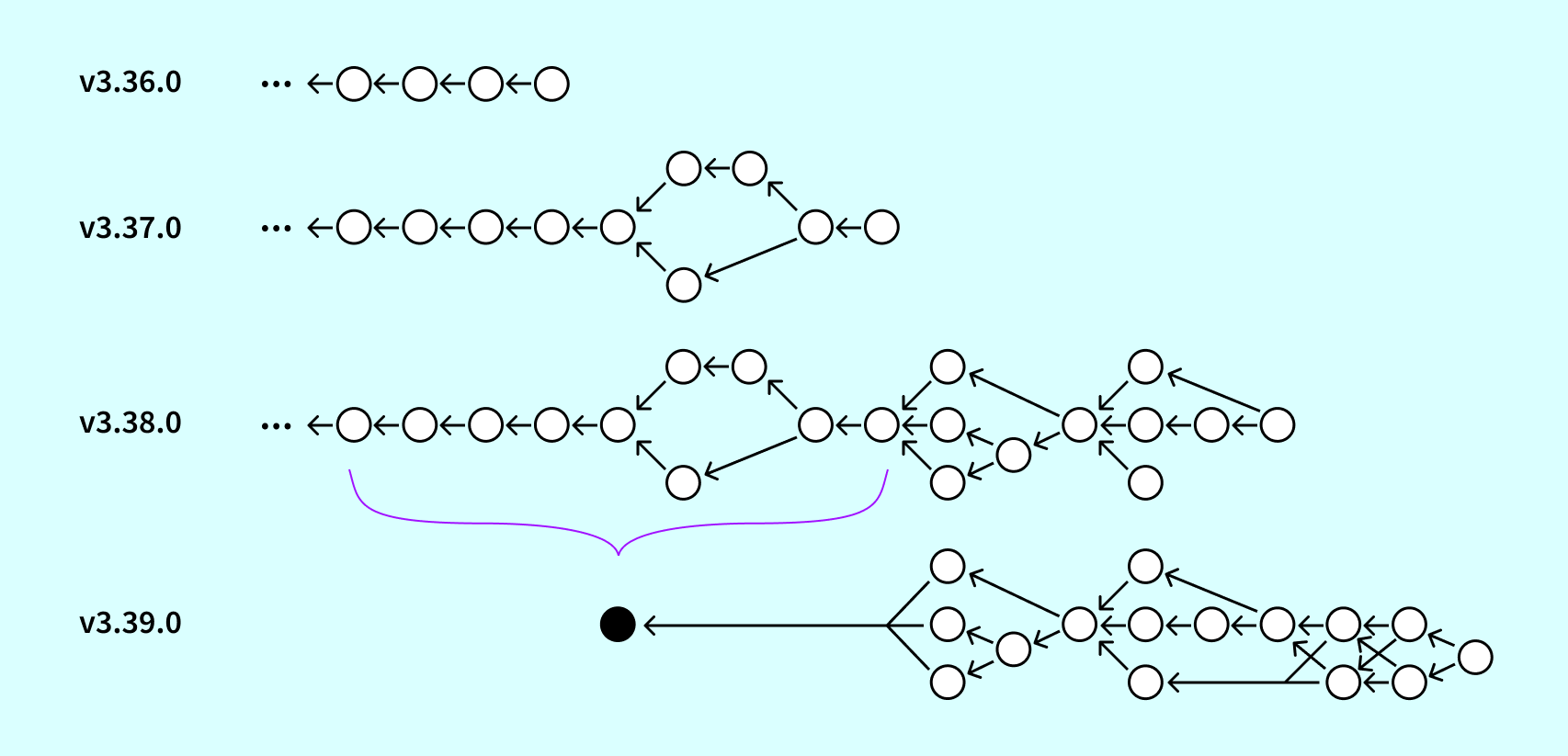
The pile of wrenches
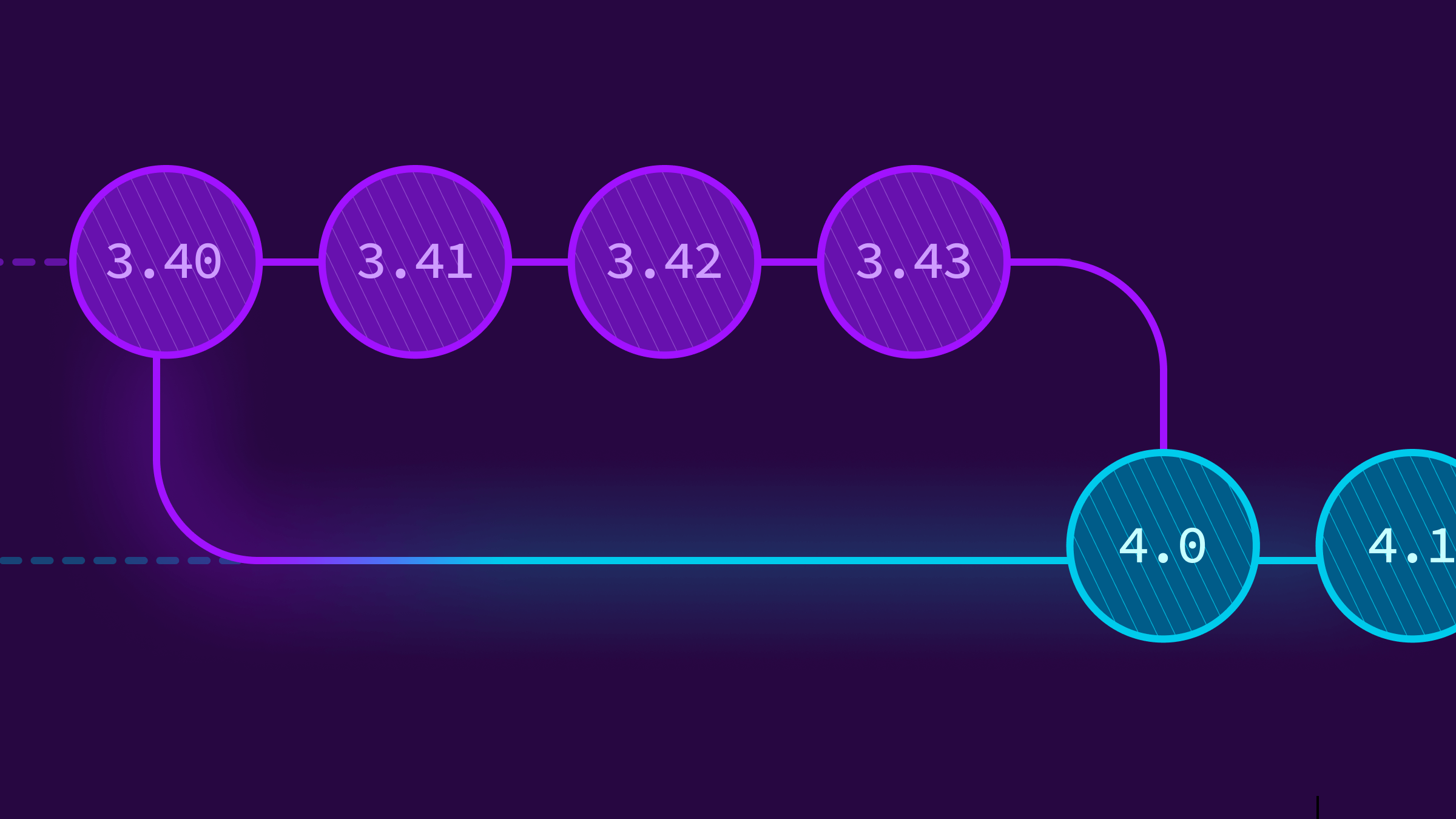
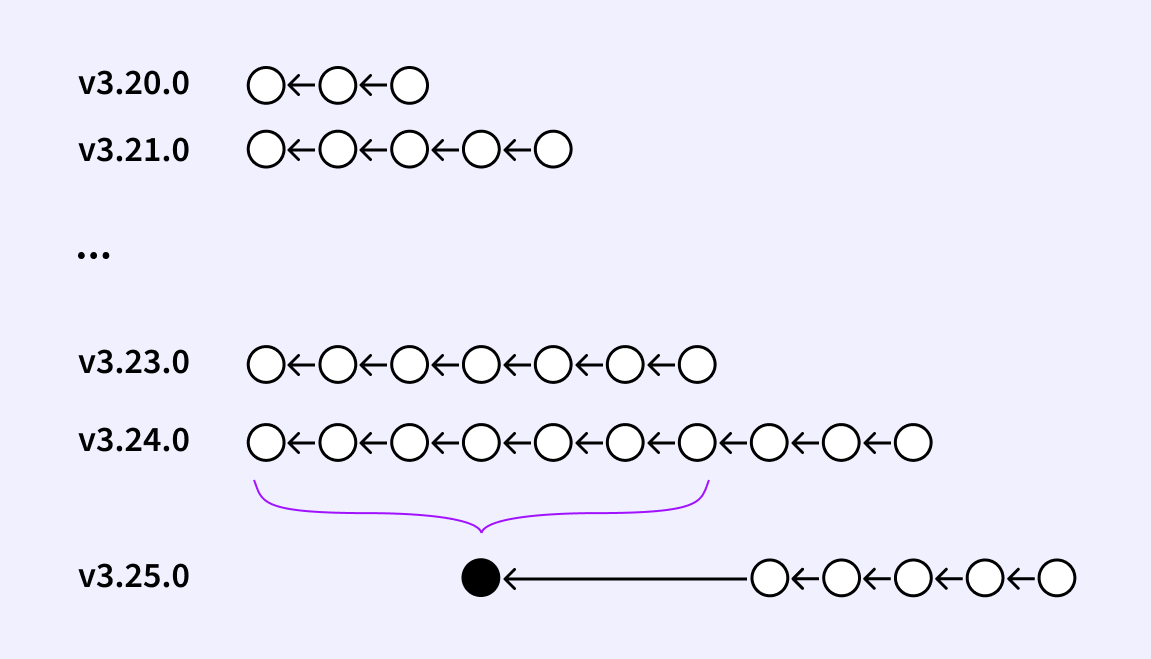
The evolution of our migration definitions over time has created a number of issues to overcome for multi-version upgrades. The biggest issue comes from periodically squashing migration definitions, which erases information necessary to the upgrade process. In the image above, there’s no valid way to upgrade from 3.36 to 3.39 in one step. The squashed migration contains both the SQL that’s already been run by the 3.36 installation, as well as the SQL defined in 3.37 that has yet to be applied. As we cannot partially apply a single migration, we cannot support this upgrade path.
To get around this, we need to undo the squash operation over time to get a single, consistent “stitched” migration graph.
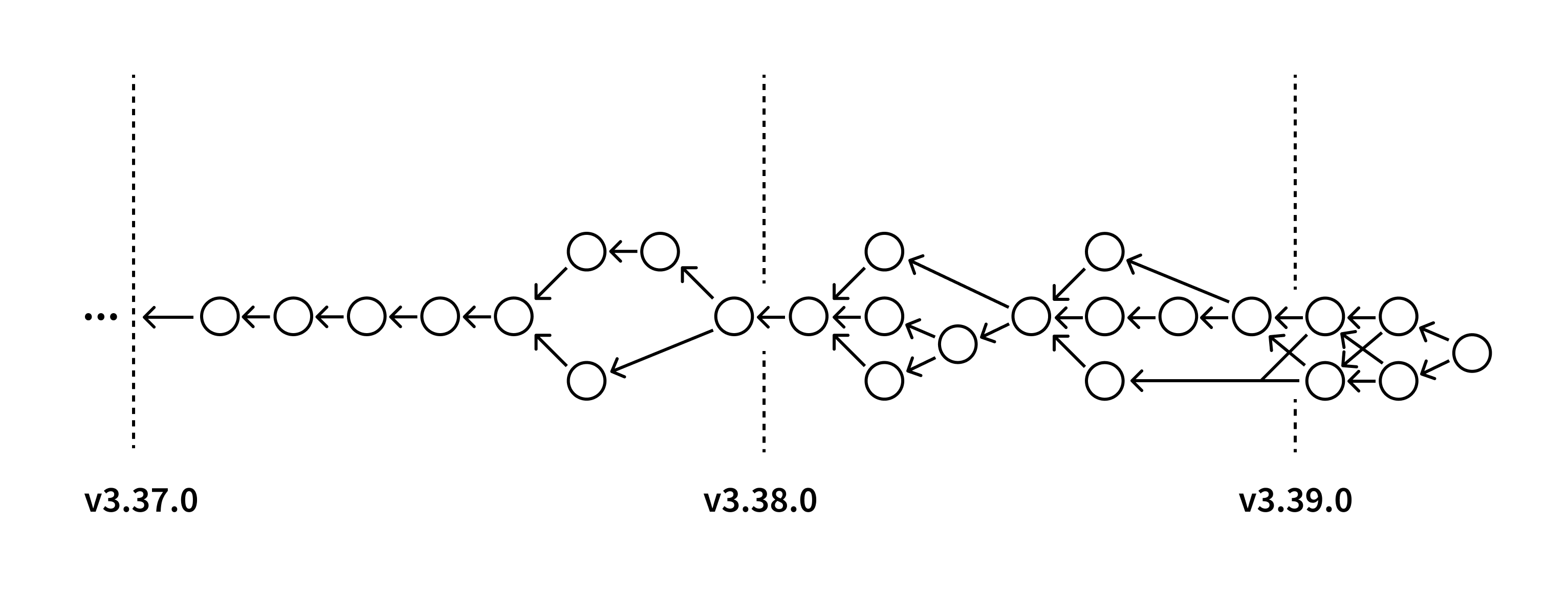
But doing so is basically time travel. For every Sourcegraph release in the upgrade support range, we take a snapshot of the migration definitions and overlay them on one another. Squashed migrations, identified by a specific naming convention, are handled distinctly in this process and provide hints on how to concatenate the migration graphs together. The result is a single unified migration graph that allows us to pinpoint any two versions and extract the sequence of SQL commands that need to be performed.
At least that was the proposed solution. The reality of this process was much more involved than the high-level overview would make it seem, as squashed migrations were only one wrench in the pile. We still had to address the others.
We threw the Wrench of Directory Restructuring onto the pile when we moved our list of flat files into a hierarchy on disk. The snapshots we take of migration definitions at a particular release are done via git operations. When we detect a flat file, we will on-the-fly rewrite it to look like the new hierarchical version, with inferred contents for the metadata. Similarly, the Wrench of Adding Additional Databases was thrown onto the pile with the introduction of distinct codeintel and codeinsights schemas. We need to take special care in the early versions we support when one or more of these schemas are not yet defined, as well as the case where only the frontend schema is defined in a different location (migrations/ vs migrations/frontend once its siblings have arrived).
We threw the Wrench of Privileged Migrations onto the pile when we started marking certain SQL commands as requiring elevated permissions. Migration definitions that contain such a SQL command and don’t mark it (or mark it but do not contain such a SQL command) fail static validation. Migration definitions squashed away before the introduction of this change fail these validation checks when added to the unified migration graph. In order to bring these definitions in line with our current assumptions, we will spot rewrite the metadata of such migration definitions as we stitch the graph together. We do this for several frontend (1528395717, 1528395764, and 1528395953), codeintel (1000000003 and 1000000020), and codeinsights (1000000001 and 1000000027) migration definitions.
We deal with the Wrench of Concurrent Indexes in a similar way. Migration definitions squashed away before the introduction of our special-casing of concurrent index creation will miss the markers in their metadata. In this case we only have to spot rewrite migrations for the frontend schema, but there were a significant number of them (1528395696, 1528395707, 1528395708, 1528395736, 1528395797, 1528395877, 1528395878, 1528395886, 1528395887, 1528395888, 1528395893, 1528395894, 1528395896, 1528395897, 1528395899, 1528395900, 1528395935, 1528395936, and 1528395954).
During this change we also started validating that any down-direction migrations do not create indexes concurrently. Concurrent index creation is meant to be something to aid in zero-downtime rolling upgrades where a full table lock would be difficult to acquire (or significantly disrupt production traffic). As downgrades are never meant to be an online operation, creation of older indexes can always be done synchronously. Again, there were several violations in the frontend schema that needed spot rewrites (1528395895, 1528395901, 1528395902, 1528395903, 1528395904, 1528395905, and 1528395906).
The act of stitching the migration graph itself also uncovered an additional hurdle that wasn’t entirely expected. One assumption is that, with the exception of squashed migration definitions, migrations are not modified after the release in which they were introduced. Turns out there were some valid (and a few less valid) reasons for modifying these files. Some migration files were written to be idempotent (adding IF NOT EXISTS to missing clauses) so that they can be run twice with no ill effects (a great property to strive for here). Some migration files had errors that were discovered only after the branch cut of that release (dropping the wrong index on the down direction, as the presence of the IF NOT EXISTS clause silenced the error). For each of these cases, we confirmed that the newer version should be used in place of the older one, and specifically allow rewrites for several migration definitions: frontend (1528395798, 1528395836, 1528395851, 1528395840, 1528395841, 1528395963, 1528395869, 1528395880, 1528395955, 1528395959, 1528395965, 1528395970, 1528395971, 1644515056, 1645554732, 1655481894, 1528395786, 1528395701, and 1528395730), codeintel (1000000020), and codeinsights (1000000002, 1000000001, 1000000004, and 1000000010).
There were also a number of odd-duck cases to tackle, which had existed until their squashing without being detected as buggy. To handle these cases, we had to rewrite a migration that uses COMMIT; to checkpoint work, rearrange DROP commands to respect dependency order, add a missing DROP TYPE ... command, and fix migration renaming that happened when cherry-picking into patch release v3.34.2.
After cleaning up this pile of wrenches, we have a unified migration graph that passes our validation, and can upgrade the schema of a database from any version to any other version (within v3.20 and 4.0+). Unfortunately, schema migrations are only half of the upgrade process.
Handling out-of-band migrations
Early in 2021, we proposed and implemented out-of-band migration machinery to perform large-scale data (non-schema) migrations in the background of the application. We needed a way to run large-scale rewrites over data on our codeintel database, which at the time held a 2TB data set. As these rewrites were pure SQL, it was tempting to put them into our existing migration infrastructure. As this was prior to our decoupling of migrations from application startup, we needed to ensure that all migrations finished within our Kubernetes health check. Failing to do so required manual engineer intervention to run the failed migration.
This happened quite frequently.
Each out-of-band migration is defined with specific bounds within which it is expected to run: an introduced version matching the Sourcegraph release in which it first starts running in the background, and an (eventually set) deprecated version matching the first Sourcegraph release in which it no longer runs. When running a Sourcegraph release at which point an out-of-band migration is deprecated, the application startup sequence validates that the migration has completed. If the migration is incomplete, then there may be data that is no longer readable by the new version, and the adminstrator is instructed to roll back to the previous version and wait for it to complete.
Multi-version upgrades become problematic when we cross a Sourcegraph release in which an out-of-band migration has been deprecated. We can run the schema migrations, but the application will still refuse to start when it sees the incomplete migration. Even worse, we can construct upgrade paths that are impossible to perform because they skip over both the introduced and deprecated version of an out-of-band migration.
To solve this, we also run the out-of-band migrations in the migrator, interleaved with the schema migrations.
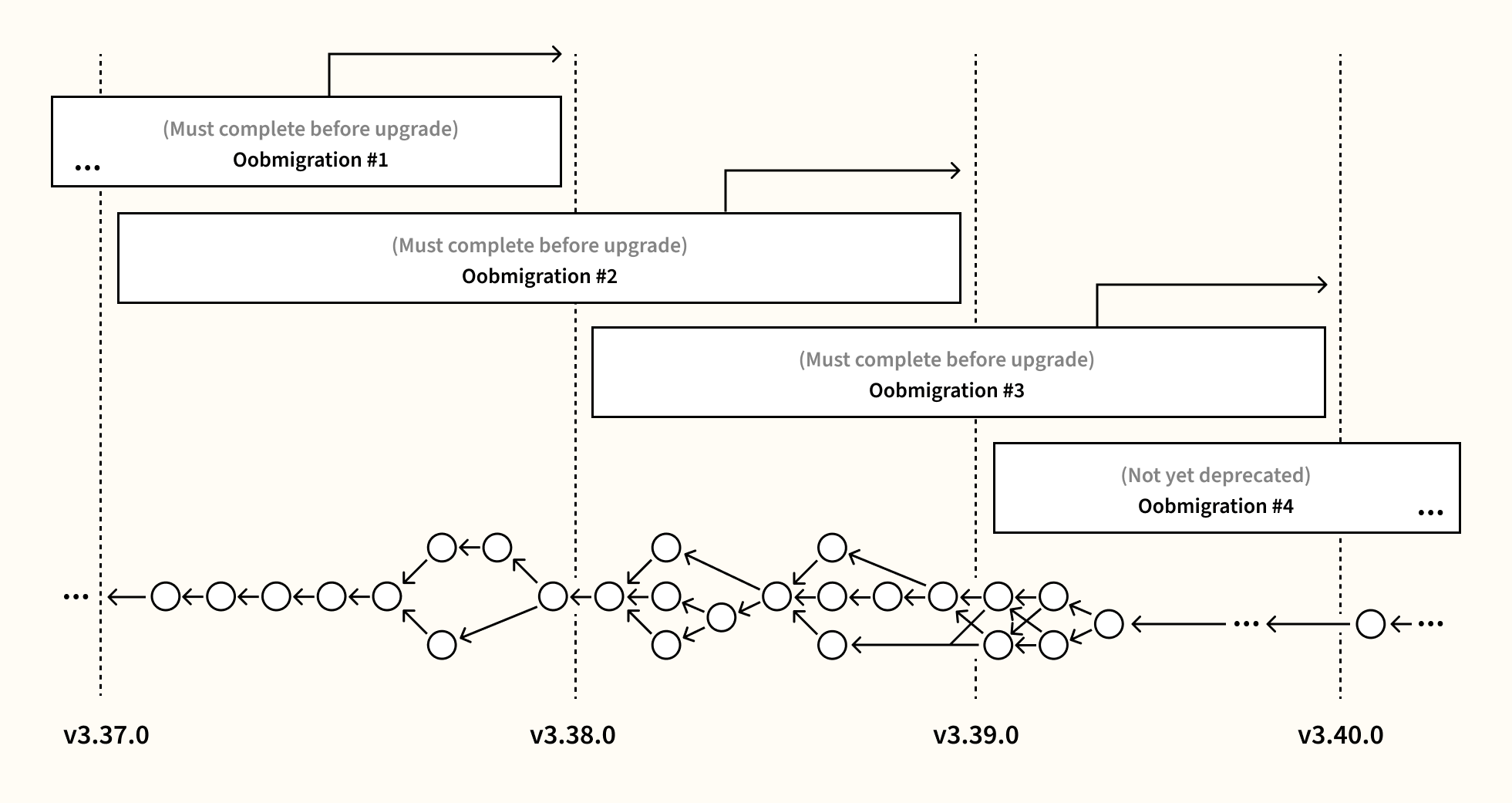
In the example above, upgrading from v3.37 to v3.40 would require the completion of out-of-band migrations #1-#3. To make things a bit more difficult, the out-of-band migration code is only guaranteed to run against the database schema that existed within its lifetime. We cannot invoke out-of-band migration #3 with the v3.37.0 database schema, for example. This becomes a scheduling problem in which we upgrade the schema to a certain version, run out-of-band migrations to completion at that point, and continue the process.
Conclusion
We’ve continued to iterate on our schema and data migration infrastructure to remove entire classes of pain from our customers, and we are taking significant strides to decrease maintenance burden. Keep your eyes peeled for future improvements in this area.
If your next upgrade goes well, let me know at @ericfritz.