When I was working as a Staff Engineer at Sourcegraph, I performed a lot of “exploratory coding” that helped determine if some nascent idea is able to stand on its own legs. If the idea was validated with sufficient confidence, it would be polished, productionized, and shipped. Sometimes the polish ended up taking the majority of the effort. Often times these ideas were backtracked and abandoned and its learnings taken back to the team to amend our frontier ideas. If a particular change didn’t move the needle enough relative to the estimated engineering effort, we’d instead focus efforts on higher-impact ideas.
That’s engineering, baby!
Doing the work of implementing an idea, even a small bit of it, has vast benefits in building my mental model of a solution space and helps identify possible hurdles which may be otherwise overlooked in more “purely-theoretic” planning.
Over four years, I ended up falling into a very particular rhythm of exploratory coding that accentuated a few core ideas:
- This exploratory code is an iterative experiment,
- This exploratory code is more likely than not going to be thrown away, and
- A working result is the the ultimate goal here, through whatever quick or surgical means get you there. Note that the result here is not necessarily a working code artifact, and could be something as intangible as a better understanding of the existing code or domain.
As a corollary, the code being iterated over was for me, and outside eyes were expected to eventually gaze upon a rewritten history of what I learned rather than the crazy wall scribblings that catalogued the dead ends that taught me the lesson.

The crazy wall scribblings
My working drafts are not meant for public consumption and likely constitute a cognitohazard for others. They may make little sense outside of the specific journey I’m taking to solve a particular problem.
I’ll move existing code out of the way in what can’t legally be called a “refactor”. I’ll leave unit tests in a broken state. I’ll implement new functionality for the minimal portion of interface implementations and leave the build in a broken state. These things are easy to come back to (and impossible to forget with literally any form of continuous integration).
Well, the code is relatively messy, but at least the commit messages track my progress. Right?
No!!!
WIP. WIP. WIP.
That’s it. That’s all you get. That’s the entire branch history.
I have a git alias, git wip, specifically slamming the entire repo state into a progress commit. Code made a bit of progress? Slam F5 to auto-save. It’s how I play video games, and it’s how I checkpoint my own progress in experimental branches. What a waste to learn two habits when one will do! Honestly, if I was doing this pre-Git, I likely would’ve copied the entire file and renamed it to NewFinalestDone_Final2 1. I’m not at all above that.
The current state of code is my current progress, state of mind, and todo list. If I feel the need to go back in time to save something, I’ll keep it around as dead (or commented out) code. There is no expectation of code cleanliness at this stage of experimentation.
But at some point, you have to ship. And I’m in no habit of shipping slop.
Focused changes
[We] want to establish the idea that a computer language is not just a way of getting a computer to perform operations but rather that it is a novel formal medium for expressing ideas about methodology. Thus, programs must be written for people to read, and only incidentally for machines to execute.- Harold Abelson in the Preface to the First Edition of SICP
Code is, at its core, a way for humans to precisely define to other humans how a machine is meant to solve a particular problem. This is largely why literate programming and Jupyter notebooks are such beautiful ideas and Malbolge is a crime against the very essence of communicable thought.
At some point in an experimental branch I’ll reach a baseline level of confidence that a particular solution will work out. If the additional effort required to polish off the implementation is justified, I shift my focus to the task of imbuing others with similar confidence.
Unfortunately, the journey that I took that gave me confidence and the ideal explanation of the resulting solution space will be vastly different. It’s ineffective to simply hand over a branch full of half-thoughts and backtracked dead-ends and expect another person to make sense of it, let alone agree with its implicit conclusions.
There’s an impedance mismatch between learning and teaching. Learning is unfocused and searching. Teaching is structured and requires the “core ideas” to be tightly focused and unblemished by cruft, or you risk teaching the wrong lesson entirely. You cannot lean what is not taught clearly, and you cannot teach what you do not understand yourself.
Consider this git diff, which is a real extract from an experimental branch of mine. I can’t clearly explain to you intuitively what this change even is because multiple layers of the code have changed in non-uniform ways.
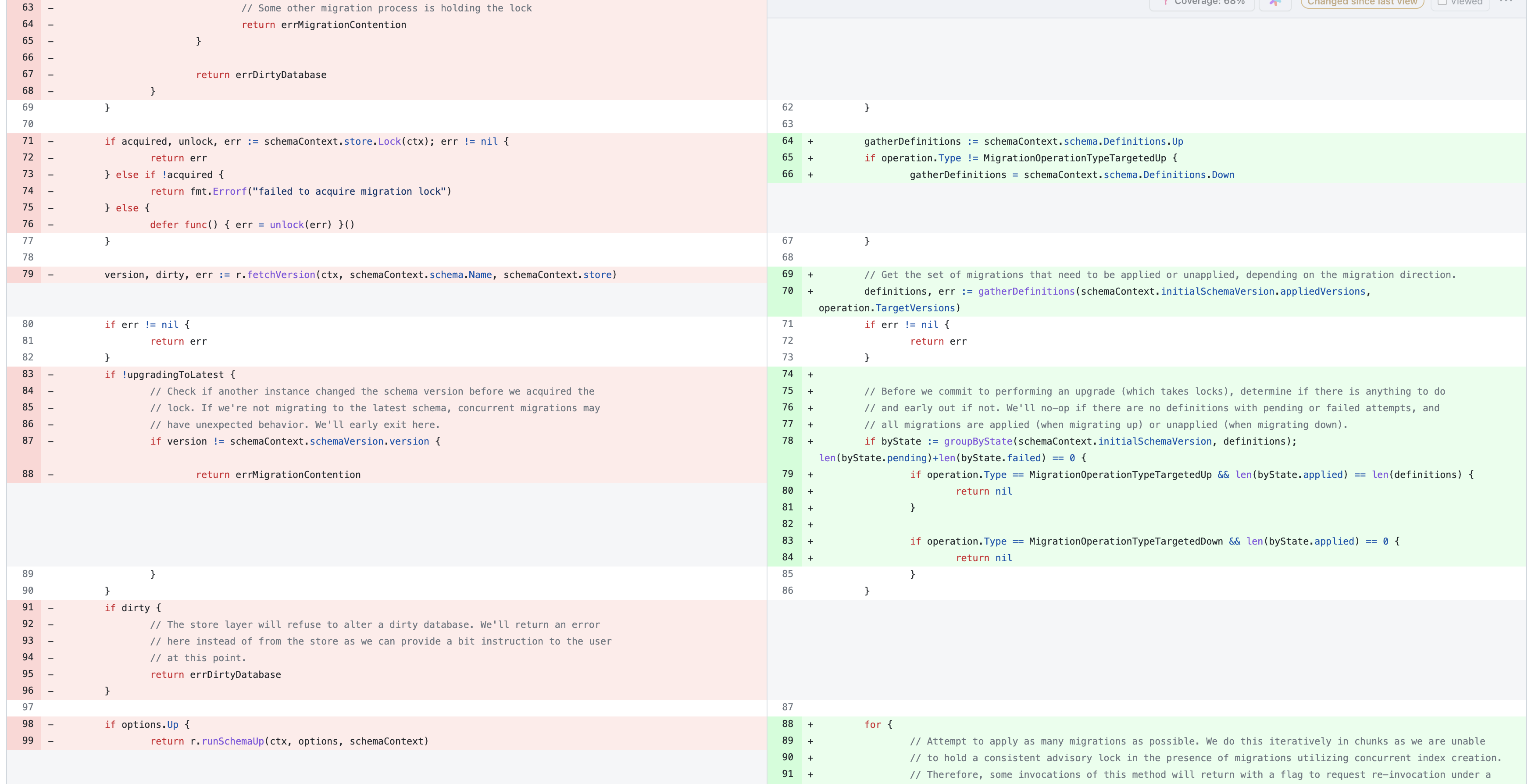
This is in no way an intrinsically bad change - each modification here was a necessary part of a holistic whole. But the specific presentation as one atomic change does nothing to make any of the individual decisions made as part of the change explicit. There are too many concerns to explain at once.
When you present cross-cutting changes to a reviewer, you encourage them to understand it at only a surface level. They’ll likely focus on reviewing your pull request description rather than the actual changes you made to the system in-depth, and you’ll receive at best a “LGTM” stamp. Such reviews are a disservice to pull requests as a method of sharing context, as nothing has been taught.
Contrast this with multiple, focused changes that sum to the same whole. The first change inlines the funtions runSchemaUp and runSchemaDown at their call site by applying UpTo or DownTo followed by applyMigrations. This refactoring step is made in service of making a subsequent change more focused an easier to reason about, but can still stand on its own as an improvement to the code.

The second change invokes applyMigrations in a loop until an invocation errors or otherwise indicates that it has finished all of the work it needs to do. This is the core behavioral change made in the original diff, and is presented without the surrounding code being Tower of Hanoi’d out of the way.

Isolating independent changes for individual review in this way can massively decrease the mental burden for the reviewer, who can use the additional capacity for higher quality review and more effective updates to their own mental model of the shared system. Code changes should always happen for a defensible reason, and the onus of a cogent change is on the author, not the team.
Rewriting for the reviewer
The real work of an engineer begins when a working solution must be converted into a convincing argument for others. Coding itself is the (relatively) easy part of the job. Good programmers write decent programs. Great programmers manipulate the wetware of their colleagues.
I’ve found that the translation from a working branch to something worthy of a second pair of eyes is an art. There’s no single optimal algorithm for constructing a well-argued pull request. It depends highly on the size, complexity, risk, subtlety, and impact of a change, as well as the audience you’re targeting.
But in overall shape, I’ve found that my process takes one of three basic forms.
Simple squash
The first, and simplest, of the three forms is to simply erase the cruft history and reuse the same branch.
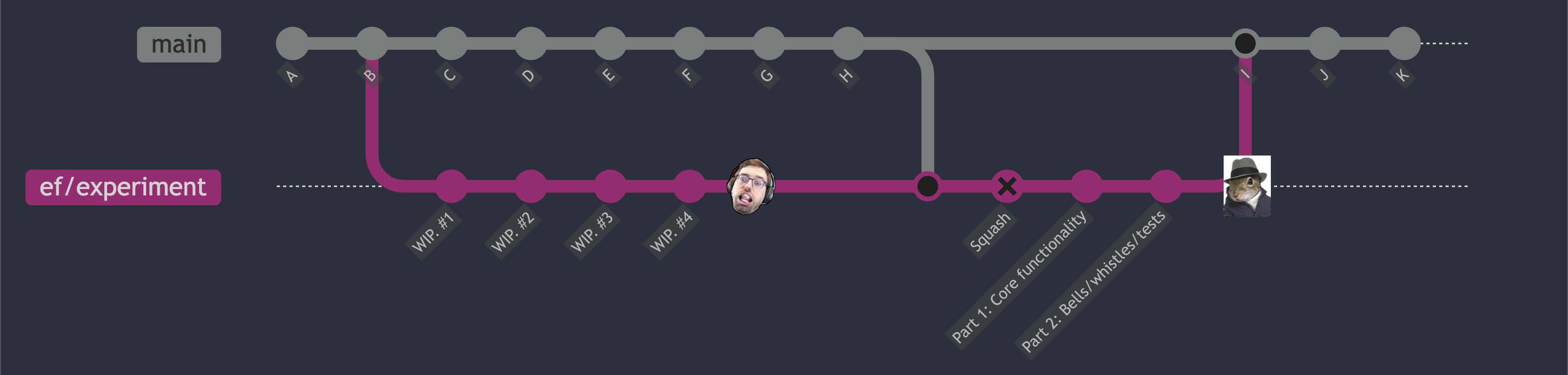
I have a dual to my git wip alias. It’s called git squash and it forcibly compresses the entire branch into a single commit. The state of the experimental branch is the artifact I want discussed. I do not want to leave around irrelevant historical information that could distract from the current state of the solution.
When the change, in the end, is relatively simple, it may be reviewed in a single shot. For slightly more complex changes, I may want to do some additional molding over the order and grouping of the changes and break it into several commits each with a specific focus. This allows review-by-commit which can form a narrative for easier review. Generally, it’s rare that branch is written along the same dimensions and in the same order that it should be reviewed.
Fresh start
The second of the forms is similar, but uses a clean slate to reconstruct a more public version of the branch. The experimental branch can be used as a frozen checklist of what must be present in the polished version.
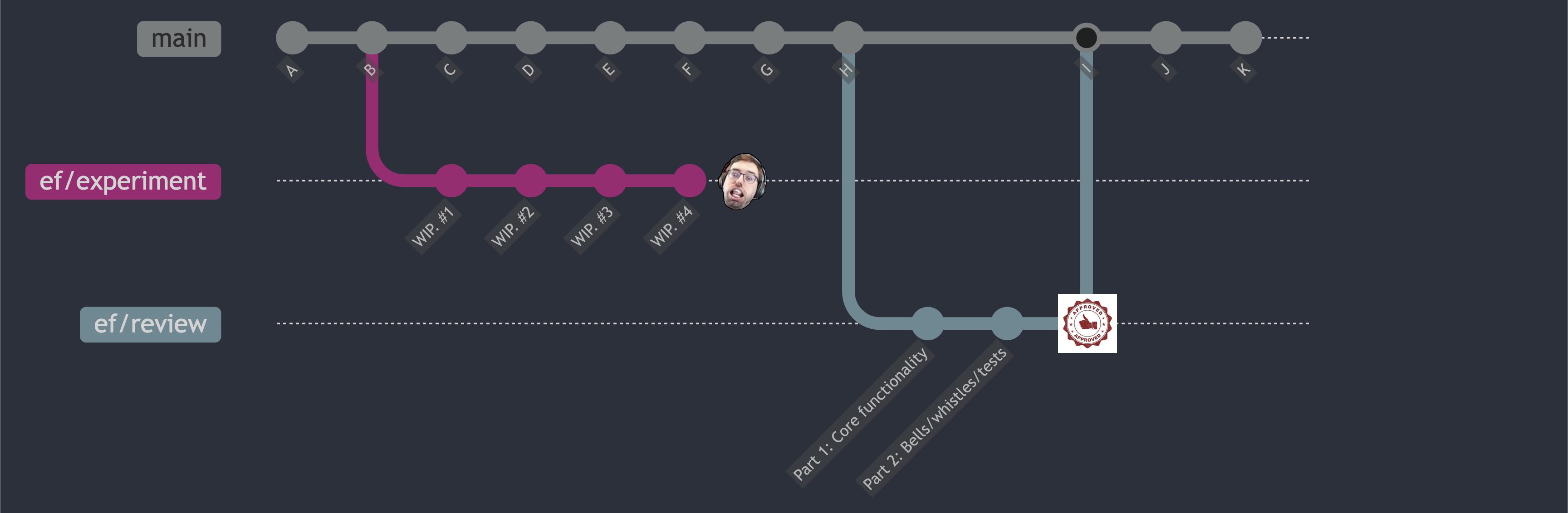
Piecewise reconstruction
When the change gets complex enough, a single branch or review cycle may not be sufficient.
A change touching many parts of a system may require multiple sets of reviewers, where each reviewer may only care about the slice of the change that affects their ownership. In these cases, it’s ill-mannered to present a massive change and request that they only pay attention to a subset of it. In fact, that is precisely another action that encourages reviewers to only understand the code at a glance. Multiple reviewers looking at non-overlapping areas of a single change will inevitably lead to un-reviewed gaps, where bugs hide and knowledge falls, lost to the void.
Fortunately, there’s no restriction requiring that the experimental branch stay as a single reviewable atomic change. The third form uses multiple clean slates, decomposing the original branch into as few cross-cutting concerns as possible.
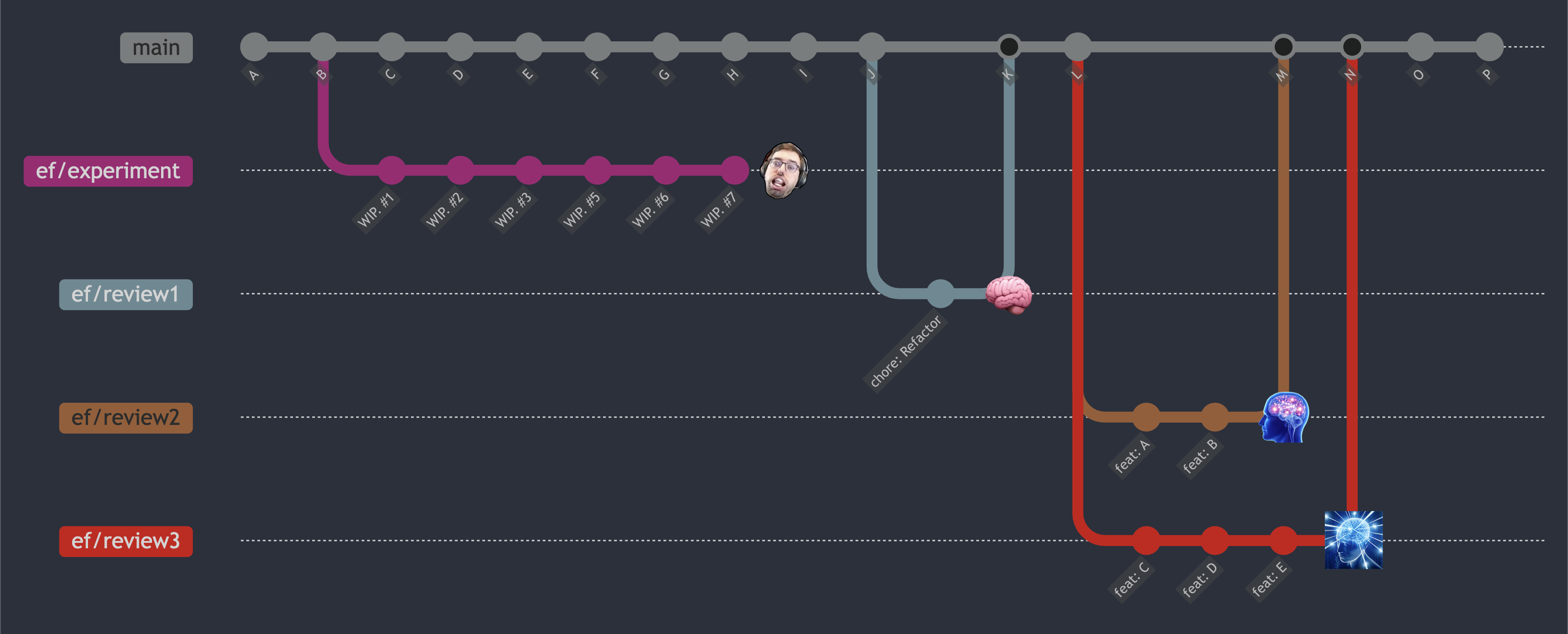
Each subsequent pull request can then be argued in a direct and concrete manner (while still in the context of a larger effort), and reviewed by precisely the engineers to which the change is relevant. Mechanical and refactor changes, which can muddy what’s directly relevant to the intended change, can be broken out into behavior-preserving pull requests that can be merged in ahead of time.
Rewrites in practice
To demonstrate how this form works at scale, I’ll refer a portion of a large-scale change to Sourcegraph’s upgrade and migration strategy from 2022. The overall strategy is discussed deeply in RFC 469: Decouple migrations from code deployments. The portion of the implementation relevant here involves converting SQL migration definitions from a sequentially numbered list to an acyclic graph. This structure helped to reduce the number of conflicts during development when multiple engineers were modifing non-overlapping parts of the database schema.
My working branch for this effort required a lot of changes to existing code (dominated by changing the format of every SQL migration file). The number of altered files actually turned out to be a hurdle to even requesting a review, as the pull request on GitHub would fail to stay responsive.
If I had sent this out for review in one large chunk, I’d expect only crickets. Possibly a flaming bag on my porch. Thankfully, that version of the branch was never meant to be atomically merged in. The description of the pull request, forever in draft mode, stated exactly that:
This branch is an experiment (never meant to be merged) to ensure that a set of migration features, when implemented to completion, work well together. Now that this has been proven, this effort will be cut up into smaller, more digestible chunks.
The PRs that come from this branch will be linked here. Periodically, I may merge an updatedmaininto this branch to “checkpoint” completed work. This will reduce the diff of this experimental branch tomainto keep the relevant portions of the experiment that are still in discussion focused.
True to this plan, I iteratively cut forty five distinct changes out of this experiment for individual discussion and review, merging the new and partially-integrated state of the main branch back into the working solution.
It got smaller and smaller with every extracted change merged. The checklist of what needed to be extracted reduced in tandem. Eventually, there was nothing left and that signaled a successful merge of the entire branch.

The extracted changes fell into four different classes.
The first class is added code, which introduced code that provided a functionality that did not previously exist. Often, this code was not yet “hooked up” to the application, so it and its tests existed silently until a subsequent change would plug it in, often in the place of old code. Changes in this class include #30270, which adds an (initially unused) IndexStatus function that reports the progress of an index being created concurrently.
Another interesting example includes #30321, which introduced utilities for working with a graph structure: ways to determine the roots, leaves, and dominators of the graph, as well as handle traversals. These utilities were introduced separately to target specific reviewers with higher familiarity with the algorithms.
The second class is changed code, which altered existing behavior. This is the class of code that needed the most in-depth review, and had the highest impact of knowledge transfer. Changes in this class include #30276, which updated the logic to read the SQL migration definitions from disk. This required changing the format of all existing migrations and touched over 727 files overall. To help reviewers confirm correctness, the existing migration files were rewritten by a script, which was included in the first and deleted in the last commit of the pull request.
The most interesting example in this class includes #30693, which was an incidental discovery of a massive bug that plagued Sourcegraph with failed upgrades for months. It turns out that we were hitting a particular unresolvable deadlock condition with advisory locks and concurrent index creation, which was covered more depth in this blog post. This error was only discovered while working on this experimental branch and seems unlikely to have been found under other circumstances.
Having room to experiment pays dividends on your understanding of the problem space.
The third class is chore code, which focused on mechanical updates, refactors to help future changes stay focused, and trivial improvements. The fourth class is removed code, which focused on removing dead code that was used by a the previous migration structure and was no longer relevant after the new or change code was merged.
The following table shows a complete timeline of the experimental pull request #29831 represented by the purple line. This line stretches from commit 1d92f6c, the commit on the main branch from which the experiment branched, and extends through f7b2939, which is the merge commit of the last extracted pull request. Everything else was extracted from this root branch and polished for individual review. It was possible to have many streams of extraction and review occurring in parallel, especially refactors of different parts of the codebase.
Takeaway
Code for people, not for machines. The ability to communicate your ideas to humans - whether or not those ideas are expressed in a precise language also understandable by machines - is a worthwhile skill to develop.
I also use print line debugging daily. ↩︎