Deposition (described in a previous article) is a tool used to track the dependencies and vulnerabilities of a software project. This product belongs to a class of tools that benefits greatly from the existence of an audit log.
Most of the time, modifications to data via the API are performed by a build user in the context of a continuous integration system. The API and the UI does allow data to be altered and overridden. Products and builds can be deleted. Dependencies can be flagged and flags can be removed. Admin users can modify team membership and other user’s capabilities. Users can create deployment overrides that allow flagged dependencies into a production environment. Some of these actions can be dangerous, and the presence of an audit log can help to undo actions that should not have been performed, and deter actions that are performed outside of good-faith.
The following screenshot shows a view of the audit log. The summary column gives a terse description of the action that was performed, along with links to any foreign entities that still exist.
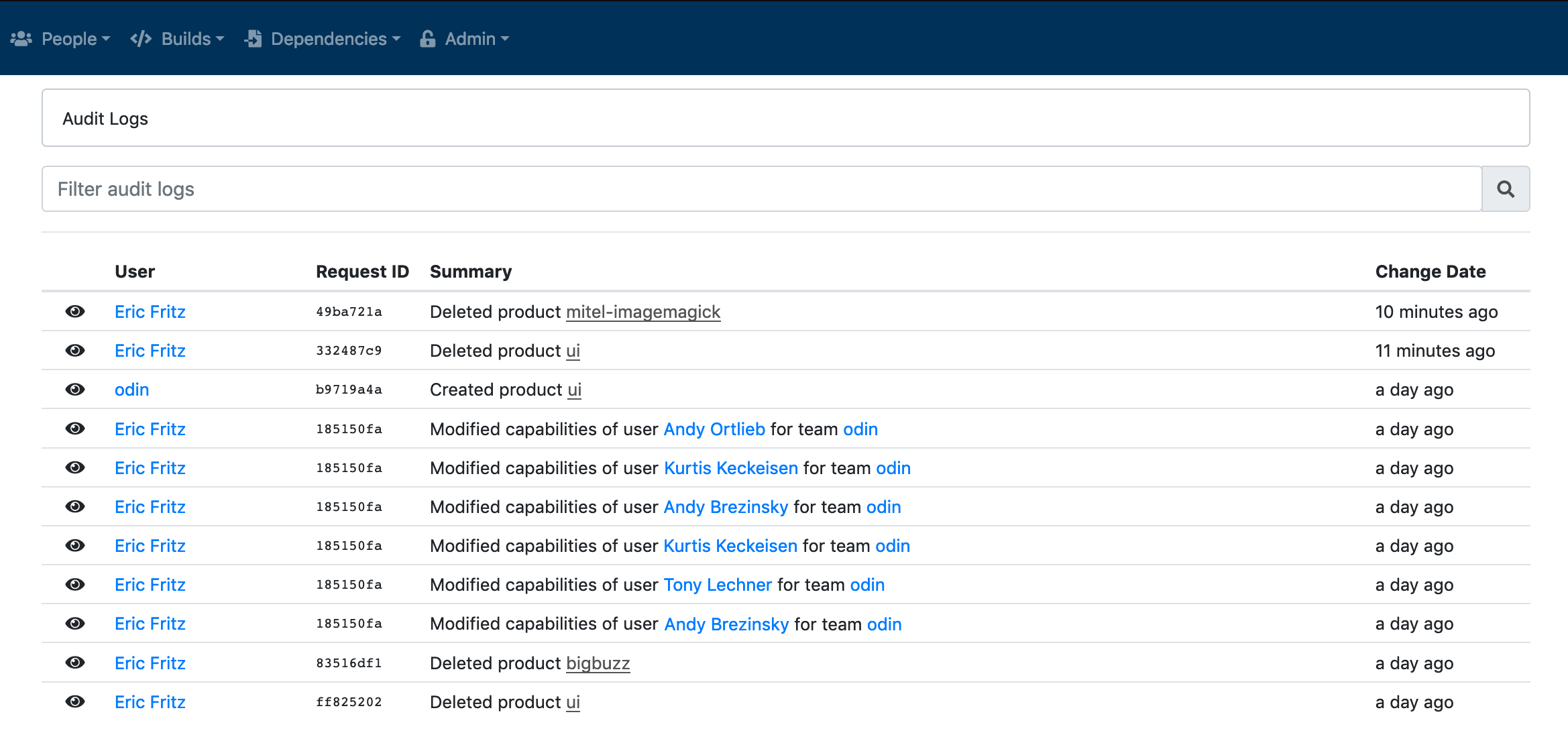
The following screenshot shows a detailed view of one audit log record, which shows the difference of the values in the database before and after the operation was performed. For a record update, this dialog shows the before-and-after values of the columns that were altered. For creation and deletion of records, this dialog shows the entire record as it was after creation and before deletion, respectively.
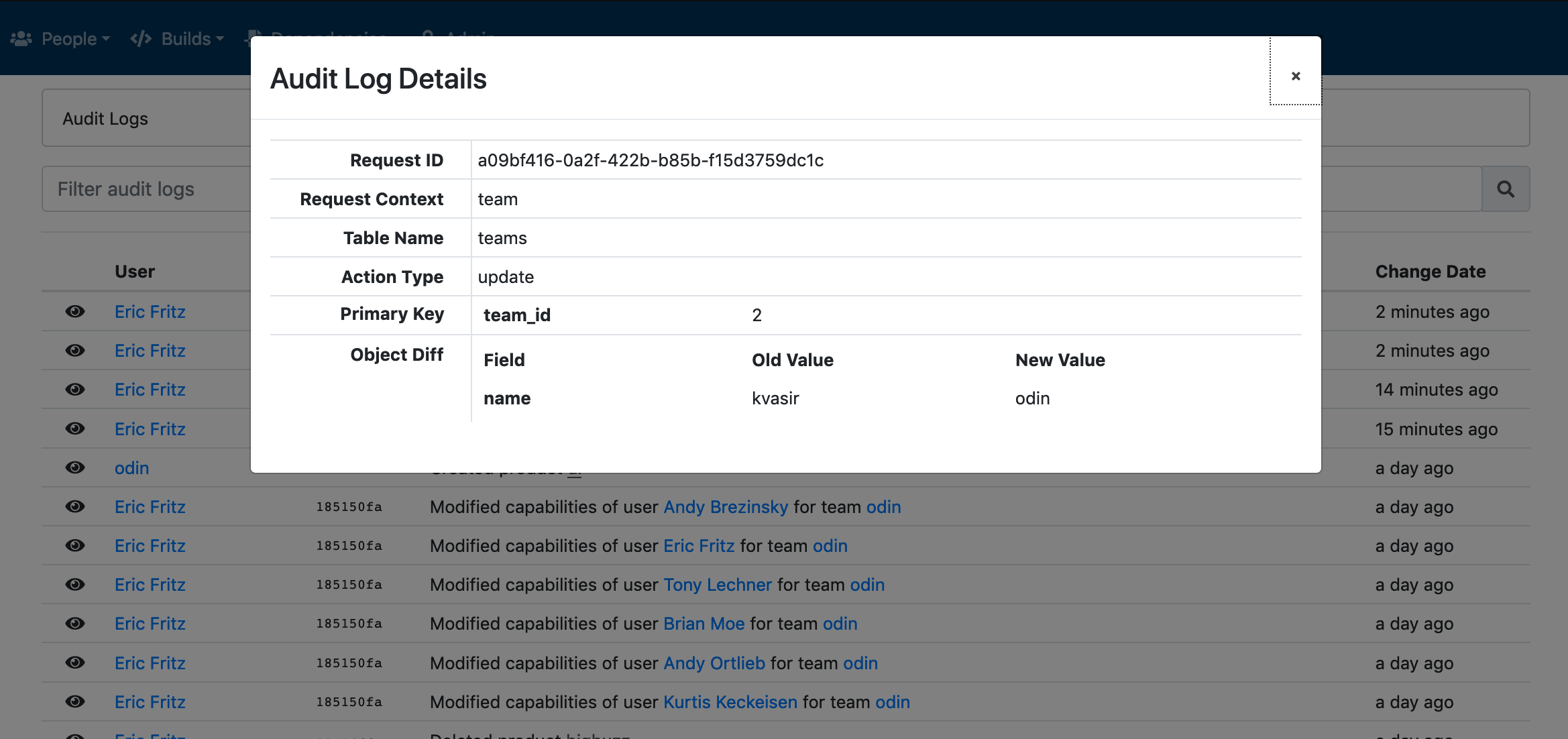
This remainder of this article outlines how PostgreSQL was leveraged to add automatic audit log insertions without changing any application code. The code here is written to work with Deposition, assuming the existence of some external tables and the semantic value of their columns. However, the technique is not tied to any particular schema and can be easily adapted to fit another application using the same database with minimal changes.
The Table Definition
First, we need to create a table to store audit log records. Each audit log row corresponds to a the modification of a single database row. To track the modifications, we store the table name, the old and new values of the row, the action type (an enum value corresponding to INSERT, UPDATE, and DELETE operations), and the time that the action was performed.
This allows us to know what changed in the database, but that’s not the useful part of the audit log. Along with each change to the database, we want to store a reference to the user that performed the action, the request ID within the API that triggered the action, and the request context (usually an endpoint name) from which the action was performed.
| |
In Deposition, users can be deactivated but cannot be deleted. This table structure may not work for applications that allow users to be completely removed. In the case that the audit log records should not be deleted along with the user, the user_id column should be made nullable.
The Trigger Definitions
Our goal is to avoid having to explicitly write any application-level code that requires insertions into the audit log table prior to a modification of another table. That method may work well if your application only cares about tracking changes to a small subset of critical data, but does not scale. Each line of ORM code or raw SQL statement in the application, as well as any function defined in the database layer that modifies data, would then require a separate audit log insertion statement to be performed transactionally. This greatly reduces the readability of the code, obscuring what data is actually being modified, and the likelihood of missing one insertion is high.
For an audit log over all entities, we need a general solution that is applied automatically in the database layer. This is an excellent use case for database triggers – each insert, update, and delete operation performed on a table will automatically trigger an insertion into the audit log table. If the statement is part of a transaction, the trigger will only be performed if the transaction is committed.
The following is the definition of the audit_insert, audit_delete, and audit_update functions, which we will later set up on each table to fire after an insert, delete, and update operations, respectively. Each trigger simply inserts a new row into the audit log table. The variables NEW, OLD, and TG_TABLE_NAME are implicit populated on trigger invocation. The NEW variable holds the row values after insertion or update. The OLD variable holds the row values before update or deletion. The TG_TABLE_NAME is the name of the table to which NEW and OLD values belong.
In order to track the user and request context, we use system administration functions. Settings can be applied to a session from the API so that each query or operation performed within that session can read the setting values. These triggers assume that the API has set the user id, the request id, and the request context prior to performing a query.
The update case is a bit different than the insert and delete cases. We only want to add an audit log record if a row was actually updated. We use a helper function, num_audit_changes, to count the number of rows that have changed between NEW and OLD and only perform an audit log insertion if this value is non-zero. This helper function selects each column name from the jsonified NEW value, removes each column for which the NEW and OLD values are non-distinct, and returns the count of the remaining columns.
| |
In Deposition, we want to remove any sensitive data from the audit log table. This includes a secret column on the users table (which is properly bcrypted, but still better not to leak from the application). Because we store old and new row values as binary JSON, it is trivial to remove a column. Additional columns can be removed in the same way.
Additionally, Deposition uses a highly denormalized database structure for efficient lookup queries. The active_flagged, active, deploy_flagged, deployed, and flagged columns are all denormalized boolean columns. We don’t want audit logs to show such unnecessary information, so we do not count them as part of the column change count. This set of columns can also be easily altered (although if the column name is ambiguous, it may be necessary to also compare the table name as well).
The Trigger Applications
For the triggers above to be useful, they need to be applied to a table. For each table T in the application for which changes should be tracked, the following three statements must be performed.
| |
A word of caution: Do not track the audit log table itself.
The API
The last remaining piece, and the only modification to the application code, is to set the user and request context prior to each API request. In Deposition, we did this inside the base class for protected resources, after routing and user authentication. This type of query can be performed regardless of framework and language, and API post-authentication middleware generally seems like a secure place to perform this action.
| |
In Deposition, we also have worker processes that could modify the database. The jobs accepted by the worker process were generally tagged with the user and request context that created the job. Some jobs are run on a schedule (CVE scanning, for example), in which case they were given a canned user and a unique request context. The same query above is run after accepting a job to ensure that the audit log is correctly updated with any modifications that are performed asynchronously from the API request.